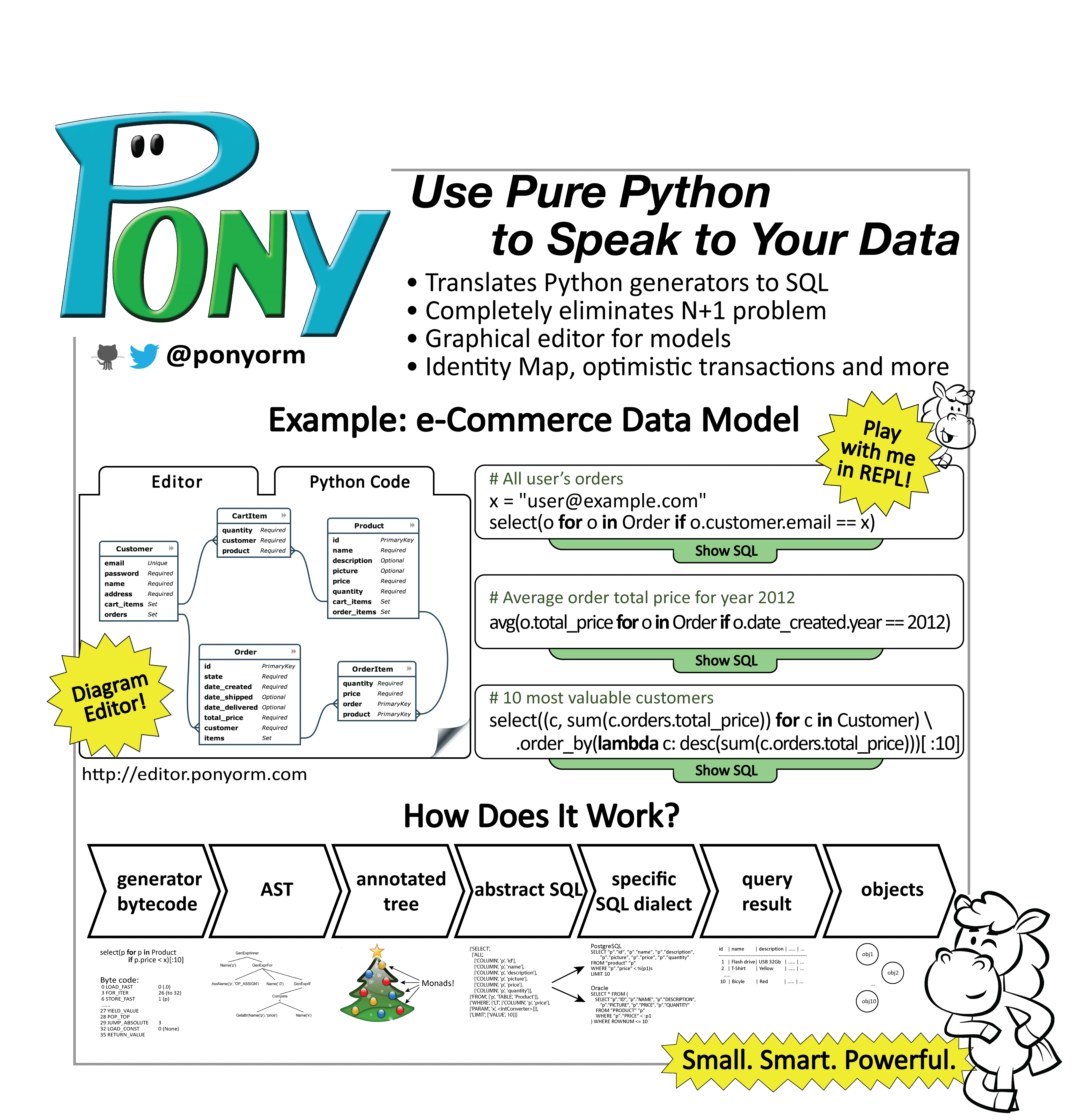
New transaction model
Before this release Pony supported two separate transaction modes: standard and optimistic. In this release we’ve combined both of them into one. Now user can choose which locking mechanism should be use for any specific object. By default Pony uses the optimistic locking. This means, that the database doesn’t lock any objects in the database. In order to be sure that those objects weren’t updated by a concurrent transaction, Pony checks the corresponding database rows during update.
Sometimes a user might want to go with the pessimistic locking. With this approach the database locks the corresponding rows for the exclusive access in order to prevent concurrent modification. It can be done with the help of for update() methods. In this case there is no need for Pony to do the optimistic check. You can use any of the following methods:
prod_list = select(p for p in Product if p.price > 100).for_update()
prod_list = Product.select(lambda p: p.price > 100).for_update()
p = Product.get_for_update(id=123)
Pony ORM transaction processing is described in more detail in the newly created documentation chapter Transactions.
Documentation
In this release we have added the ability to add comments to our online documentation, please leave your feedback, questions, comments. We need you in order to make Pony ORM documentation better.
Filtering the query results
With this release we introduce a new method of the Query object: filter(). It can be convenient for applying conditions for an existing query. You can find more information in the documentation
Database late binding
Pony ORM users were asking us to provide a way to bind the database at a later stage. This is convenient for testing. The goal of Pony ORM team is to provide a convenient tool for working with databases and in this release we’ve added such a possibility.
Before this release the process of mapping entities to the database was as following:
db = Database('sqlite', 'database.sqlite')
class Entity1(db.Entity):
...
# other entities declaration
db.generate_mapping(create_tables=True)
Now besides the approach described above, you can use the following way:
db = Database()
class Entity1(db.Entity):
...
# other entities declaration
db.bind('sqlite', 'database.sqlite')
db.generate_mapping(create_tables=True)
Other features and bugfixes
- Added method Query.page() for pagination
- Added count() method for collections. E.g.
Customer[123].orders.count() - Added ORDER BY RANDOM():
MyEntity.select_random(N),MyEntity.select(...).random(N),select(...).random(N)– N is the number of elements to be selected - Bugfix in
exists()subquery - Bugfix when the same item was added and removed within the same transaction
- Aggregations bugfix
- The support of PyGreSQL is discontinued. Using psycopg2 instead
- Added
pony.__version__attribute - Stability and performance improvements